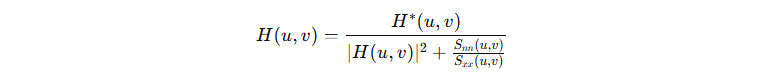OpenCV Extra 2D Features Framework 정의
OpenCV Extra 2D Features Framework는 OpenCV 기본 라이브러리에서 제공하지 않는 고급 특징 추출(Feature Detection) 및 특징 기술자(Descriptor) 알고리즘을 제공하는 확장 모듈입니다. 이 기능은 OpenCV의 확장 저장소인 opencv_contrib에 포함되어 있으며, 컴퓨터 비전 분야에서 객체 인식, 이미지 매칭, 로봇 비전, 증강현실(AR) 등의 다양한 응용에 활용됩니다.
기본 OpenCV 패키지에는 ORB, FAST 등 일부 특징 검출 알고리즘이 포함되어 있지만, 연구나 고급 프로젝트에서는 더 다양한 알고리즘이 필요한 경우가 많습니다. 이를 해결하기 위해 제공되는 기능이 바로 Extra 2D Features Framework입니다.
대표적으로 다음과 같은 알고리즘을 제공합니다.
- SIFT (Scale-Invariant Feature Transform)
- SURF (Speeded-Up Robust Features)
- BRIEF
- FREAK
- LATCH
- DAISY
이 알고리즘들은 이미지에서 의미 있는 특징점(Keypoint)을 검출하고, 이를 설명하는 특징 벡터(Descriptor)를 생성하여 이미지 간의 유사성을 분석하는 데 사용됩니다.
OpenCV Extra 2D Features Framework 설명
OpenCV에서 Extra 2D Features는 cv2.xfeatures2d 네임스페이스를 통해 사용할 수 있습니다. 이 모듈은 기본 OpenCV 패키지에는 포함되어 있지 않으며 opencv-contrib-python 패키지를 설치해야 사용할 수 있습니다.
1. 설치 방법
pip install opencv-contrib-python설치 후 다음과 같이 모듈을 확인할 수 있습니다.
import cv2
print(dir(cv2.xfeatures2d))2. 주요 특징
1) 다양한 특징 기술자 제공
기본 OpenCV보다 훨씬 다양한 feature descriptor 알고리즘을 사용할 수 있습니다.
2) 연구 및 산업 프로젝트 활용
SLAM, 로봇 비전, 3D Reconstruction 등 다양한 컴퓨터 비전 프로젝트에서 활용됩니다.
3) 강력한 특징 매칭 성능
이미지의 회전, 크기 변화, 조명 변화에도 비교적 안정적인 특징을 추출합니다.
4) OpenCV와 높은 호환성
기존 OpenCV Feature2D 인터페이스와 동일하게 사용할 수 있어 코드 통합이 쉽습니다.
OpenCV Extra 2D Features 활용 예제
다음 예제는 SIFT 알고리즘을 사용하여 이미지의 특징점을 검출하고 시각화하는 Python OpenCV 코드입니다.
import cv2
# 이미지 읽기
img = cv2.imread("image.jpg")
# 특징 추출 정확도를 높이기 위해 grayscale 변환
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# SIFT 객체 생성
# Extra 2D Features Framework에서 제공되는 대표 알고리즘
sift = cv2.SIFT_create()
# 특징점(Keypoint)과 Descriptor 계산
# detectAndCompute 함수는 특징점 검출과 descriptor 생성을 동시에 수행
keypoints, descriptors = sift.detectAndCompute(gray, None)
# 특징점 시각화
# DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS 옵션을 사용하면
# 특징점의 크기와 방향 정보까지 표시됩니다.
result = cv2.drawKeypoints(
img,
keypoints,
None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS
)
# 결과 출력
cv2.imshow("SIFT Keypoints", result)
cv2.waitKey(0)
cv2.destroyAllWindows()위 코드는 이미지에서 특징점을 검출하고 이를 시각적으로 확인할 수 있도록 표시합니다. 이 방식은 이미지 매칭, 객체 인식, 파노라마 생성, 영상 추적과 같은 다양한 컴퓨터 비전 응용에서 활용됩니다.
OpenCV Extra 2D Features Framework는 OpenCV의 기능을 확장하여 고급 특징 추출 알고리즘을 제공하는 매우 중요한 컴퓨터 비전 도구입니다. 특히 이미지 매칭이나 객체 인식과 같은 프로젝트에서는 높은 정확도의 특징 검출이 필요하기 때문에 SIFT, SURF, FREAK과 같은 알고리즘이 자주 사용됩니다.

'영상처리 도구' 카테고리의 다른 글
| OpenVINO GenAI API 란? 설명과 활용 방법 (0) | 2026.03.22 |
|---|---|
| OpenCV AI Kit(OAK) 연동과 활용 방법 (0) | 2026.03.18 |
| OpenCV RGB Depth Processing 설명과 활용 (0) | 2026.03.11 |
| OpenCV를 이용한 실시간 얼굴 비식별화 방법과 활용 (0) | 2026.03.08 |
| OpenCV Tracking API 기반 객체 추적 설명과 활용 (0) | 2026.03.04 |